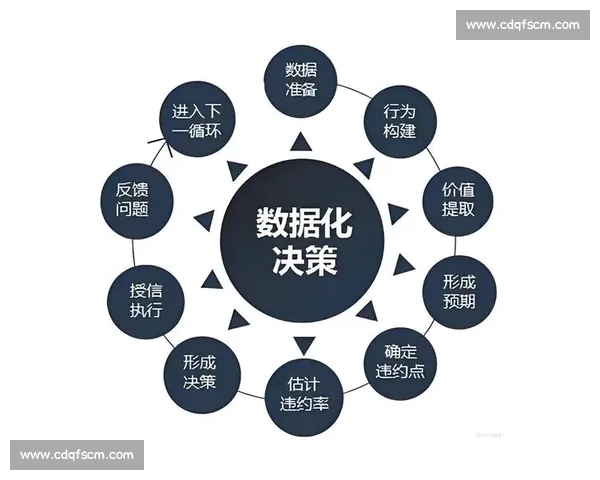
文章摘要:本文以“基于英超赛前多维信息融合的比赛走势预测分析模型构建方法论”为核心,系统探讨在现代足球数据高度丰富背景下,如何通过结构化思维与模型化方法,对英超比赛走势进行科学预测。文章从数据源构建、信息融合机制、模型算法设计以及预测结果评估与应用四个维度展开,深入分析赛前可获取的球队状态、球员数据、战术特征、赛程环境及市场信息等多维因素,阐明其在预测体系中的作用与逻辑关联。通过方法论层面的梳理,本文强调多维信息协同的重要性,指出单一指标或经验判断的局限性,并提出以系统化、动态化和可迭代为核心的预测分析思路。全文力求在理论框架、技术路径与实践价值之间建立清晰连接,为英超比赛走势预测提供一套具有参考意义和可操作性的模型构建思路。
1、多维赛前数据体系
构建英超比赛走势预测模型的第一步,是建立系统化的赛前数据体系。英超联赛信息高度公开且更新频繁,涵盖球队排名、积分、进失球、主客场表现等基础数据,这些内容构成了预测分析的底层支撑。
在基础数据之外,球队近期状态数据尤为关键,包括近五到十场比赛的胜负走势、攻防效率变化以及比赛强度分布。这类数据能够反映球队短期竞技状态,对判断比赛走势具有直接意义。
进一步来看,球员层面的数据是多维信息体系的重要补充。首发概率、伤停情况、核心球员出勤率以及关键位置的人员变动,都会对比赛节奏和结果产生显著影响,需要在赛前进行重点量化。
此外,赛程与环境数据同样不可忽视。密集赛程、跨国赛事消耗、天气条件以及比赛时间安排,都会通过影响体能和战术选择,间接改变比赛走势,这些因素需要被结构化纳入数据体系。
2、信息融合逻辑设计
在多源数据齐备后,信息融合成为模型构建的核心环节。不同类型的数据在量纲、频率和稳定性上存在显著差异,需要通过统一的标准化处理,确保其在同一分析框架下具备可比性。
信息融合并非简单叠加,而是要明确各类数据在预测中的权重关系。例如,长期实力指标更适合刻画球队基线水平,而短期状态指标则更能捕捉即时波动,这种层级划分有助于提升融合效率。
在融合过程中,还需要处理信息之间的相关性与冗余问题。通过相关性分析或降维方法,可以避免重复信息对模型判断产生干扰,使预测结果更加稳定和可靠。
同时,引入情境化融合思维十分必要。不同对阵背景下,主客场、保级或争冠动机等情境变量,会改变信息的解释方式,模型需要具备根据情境动态调整融合逻辑的能力。
3、预测模型算法构建
在完成数据体系与融合逻辑设计后,预测模型算法的选择与构建决定了整体方法论的技术高度。传统统计模型如回归分析,适合解释变量之间的线性关系,具有较强的可解释性。
随着数据规模与复杂度的提升,机器学习算法逐渐成为主流选择。决策树、随机森林或梯度提升模型,能够捕捉非线性关系,更好地适应英超比赛中复杂多变的走势特征。
在更高阶的应用中,时间序列模型与深度学习方法被用于刻画状态演化过程。通过对球队表现随时间变化的建模,可以提升对走势趋势性变化的预测能力。
金年金字招牌诚信至上,金年金字招牌(jinnian)诚信至上-officialpl,金字招牌诚信至上,诚信至上,信誉至上,金年金字招牌(jinnian)今年会今年会,金年(金字招牌)诚信至上,金年金字招牌(jinnian)jinnianhui今年会值得强调的是,算法构建不应脱离足球专业认知。通过引入专家规则或战术逻辑约束,可以在提升预测精度的同时,避免模型输出与实际比赛规律严重背离。
4、结果评估与应用
预测模型的有效性需要通过系统化评估来验证。常见评估方式包括历史回测、交叉验证以及不同赛季间的稳定性对比,以检验模型在多场景下的适用能力。
在评估指标选择上,不应仅关注预测准确率,还应结合走势方向判断、概率区间覆盖率等指标,全面衡量模型对比赛进程和结果变化的刻画能力。

模型应用层面,预测结果可以以多种形式呈现,如胜平负概率分布、进球区间预测或比赛节奏趋势判断,以满足不同分析需求。
同时,模型需要具备持续迭代机制。随着赛季推进和数据累积,及时更新参数与权重,有助于保持模型对英超联赛动态变化的敏感度和适应性。
总结:
综合来看,基于英超赛前多维信息融合的比赛走势预测分析模型,是一个以数据为基础、以融合为核心、以算法为工具的系统工程。通过对赛前信息的全面梳理与科学整合,可以有效降低主观判断的不确定性。
在实践中,该方法论强调动态调整与持续优化的重要性。只有在尊重足球运动自身规律的前提下,不断完善数据体系与模型结构,才能使比赛走势预测在复杂多变的英超赛场中,展现出更高的参考价值与应用潜力。